文|王磊编辑|秦章勇理想的AITalk第二季,时隔130天后,终于回归。
最新一季访谈中,李想不仅谈到了对人工智能的最新思考,以及当下辅助驾驶的情况,还涉及了DeepSeek、特斯拉、苹果等众多AI公司。
在李想看来,目前辅助驾驶虽然处于十字路口,但对理想影响不大,今天的辅助驾驶就像正处于黎明前的黑暗时刻,辅助驾驶行业遇到了问题,恰恰是理想证明自己价值所在的时刻。
文|王磊编辑|秦章勇理想的AITalk第二季,时隔130天后,终于回归。
最新一季访谈中,李想不仅谈到了对人工智能的最新思考,以及当下辅助驾驶的情况,还涉及了DeepSeek、特斯拉、苹果等众多AI公司。
在李想看来,目前辅助驾驶虽然处于十字路口,但对理想影响不大,今天的辅助驾驶就像正处于黎明前的黑暗时刻,辅助驾驶行业遇到了问题,恰恰是理想证明自己价值所在的时刻。

早在第一季,李想在访谈上就提出了自己的观点,理想是一家人工智能企业,我们要做的不是汽车的智能化,而是人工智能的汽车化。
面向人工智能时代,理想的逻辑是当AI成为生产工具时,人工智能才会迎来爆发时刻。
如今,人工智能的汽车化,理想已经有了具象的体现——VLA司机大模型。
李想也坦言,做VLA司机大模型,像走向一个无人区,Deepseek没有走过这条路,OpenAl没有走过这条路,谷歌、Waymo也没有走过这条路。
访谈刚开始,李想就抛出一个事实——虽然人工智能国内发展很快,但自己每天的工作时间并没有减少,仍是在增加。
这是因为大多数人还把AI当做信息工具,李想认为AI仅仅作为信息工具是不完美的,某种程度上,眼下的AI仍然是在做熵增,会增加大量的无效信息、无效结果、无效结论。
正视AI的工具属性,也是李想在过去的几个月,在内部跟很多人重点讨论的问题。
早在第一季,李想在访谈上就提出了自己的观点,理想是一家人工智能企业,我们要做的不是汽车的智能化,而是人工智能的汽车化。
面向人工智能时代,理想的逻辑是当AI成为生产工具时,人工智能才会迎来爆发时刻。
如今,人工智能的汽车化,理想已经有了具象的体现——VLA司机大模型。
李想也坦言,做VLA司机大模型,像走向一个无人区,Deepseek没有走过这条路,OpenAl没有走过这条路,谷歌、Waymo也没有走过这条路。
访谈刚开始,李想就抛出一个事实——虽然人工智能国内发展很快,但自己每天的工作时间并没有减少,仍是在增加。
这是因为大多数人还把AI当做信息工具,李想认为AI仅仅作为信息工具是不完美的,某种程度上,眼下的AI仍然是在做熵增,会增加大量的无效信息、无效结果、无效结论。
正视AI的工具属性,也是李想在过去的几个月,在内部跟很多人重点讨论的问题。

李想把AI工具分为三个层级,分别是信息工具、辅助工具和生产工具,作为信息工具时,仅具备参考价值。
如果把AI视为辅助工具,可以提升效率,比如现在的辅助驾驶功能,或者用语音的方式来进行导航,打开美团或者听歌等,它会让我们的效率更高,但仍然离不开我们。
什么时候,能真正改变我们的工作的成果以及减少工作时长,就会变成生产工具,也就是Agent(智能体)的诞生,在李想看来,那时才是人工智能真正爆发的时刻。
李想把AI工具分为三个层级,分别是信息工具、辅助工具和生产工具,作为信息工具时,仅具备参考价值。
如果把AI视为辅助工具,可以提升效率,比如现在的辅助驾驶功能,或者用语音的方式来进行导航,打开美团或者听歌等,它会让我们的效率更高,但仍然离不开我们。
什么时候,能真正改变我们的工作的成果以及减少工作时长,就会变成生产工具,也就是Agent(智能体)的诞生,在李想看来,那时才是人工智能真正爆发的时刻。

“判断Agent(智能体)是否真正智能,关键在于它是否成为生产工具。就像人类会雇佣司机,人工智能技术最终也会承担类似职责,成为真正的生产工具。”为了迎接这个时刻,理想的“VLA司机大模型”应运而生,也可以称为司机Agent,在李想看来,VLA司机大模型就是成为交通领域专业的生产工具。
其实在一个月前,理想汽车的下一代自动驾驶架构VLA就已经亮相了,VLA是视觉-语言-行为大模型,它将空间智能、语言智能和行为智能统一在一个模型里,赋予了模型强大的3D空间理解、逻辑推理和行为生成能力,让自动驾驶能够感知、思考和适应环境。
所以它既是一个能与用户、理解用户意图的智能体,也是一名听得懂、看得见、找得到的专属司机。
而李想希望这个智能体,能像人类司机一样工作,将来也能像人类司机那样创造商业价值。
在访谈中,理想还展示了搭载了VLA司机大模型的demo演示视频,在视频里,理想的这个“司机Agen”展示了和人类司机类似的智能能力,不仅具备现有的优秀辅助驾驶能力,而且还能直接通过语音的方式和人类驾驶员高效交互。
“判断Agent(智能体)是否真正智能,关键在于它是否成为生产工具。就像人类会雇佣司机,人工智能技术最终也会承担类似职责,成为真正的生产工具。”为了迎接这个时刻,理想的“VLA司机大模型”应运而生,也可以称为司机Agent,在李想看来,VLA司机大模型就是成为交通领域专业的生产工具。
其实在一个月前,理想汽车的下一代自动驾驶架构VLA就已经亮相了,VLA是视觉-语言-行为大模型,它将空间智能、语言智能和行为智能统一在一个模型里,赋予了模型强大的3D空间理解、逻辑推理和行为生成能力,让自动驾驶能够感知、思考和适应环境。
所以它既是一个能与用户、理解用户意图的智能体,也是一名听得懂、看得见、找得到的专属司机。
而李想希望这个智能体,能像人类司机一样工作,将来也能像人类司机那样创造商业价值。
在访谈中,理想还展示了搭载了VLA司机大模型的demo演示视频,在视频里,理想的这个“司机Agen”展示了和人类司机类似的智能能力,不仅具备现有的优秀辅助驾驶能力,而且还能直接通过语音的方式和人类驾驶员高效交互。

比如在通过高速收费站时,直接说出“走人工”三个字,系统就可以从ETC收费通道转向人工收费通道,在日常驾驶和泊车环节,也可以通过“前方掉头”、“C区停车”、“靠边停车”等简单指令,调整行车或泊车的路线。
换句话讲,人类和VLA之间类似人和代驾的关系,人们怎么和代驾说,就怎么和司机Agent说。
在主持人提问试驾VLA(司机大模型)的车有没有惊喜时刻时,李想颇为“凡尔赛”地表示,挺难有什么惊喜时刻,因为当你把它当做一个人看待时,它所呈现出的表现就很正常。
当然,当普通用户第一次看到VLA的测试视频的时候,仍是会惊讶于它的表现。
在谈及VLA司机大模型的时候,李想特意先感谢了DeepSeek,正是因为当初DeepSeek的开源,才让VLA推出的速度比原来的预期要快。
比如在通过高速收费站时,直接说出“走人工”三个字,系统就可以从ETC收费通道转向人工收费通道,在日常驾驶和泊车环节,也可以通过“前方掉头”、“C区停车”、“靠边停车”等简单指令,调整行车或泊车的路线。
换句话讲,人类和VLA之间类似人和代驾的关系,人们怎么和代驾说,就怎么和司机Agent说。
在主持人提问试驾VLA(司机大模型)的车有没有惊喜时刻时,李想颇为“凡尔赛”地表示,挺难有什么惊喜时刻,因为当你把它当做一个人看待时,它所呈现出的表现就很正常。
当然,当普通用户第一次看到VLA的测试视频的时候,仍是会惊讶于它的表现。
在谈及VLA司机大模型的时候,李想特意先感谢了DeepSeek,正是因为当初DeepSeek的开源,才让VLA推出的速度比原来的预期要快。

按照李想的说法,其内部原本打算要到今年年底才能做出能够满足需求的语言模型,但DeepSeek一开源,瞬间就加速了9个月的时间。
不过DeepSeeK的开源只是加速了VLA(视觉语言行动模型)的L(language语言)的部分,像VL(视觉和语言)的组合语料,无论是OpenAI仍是DeepSeek,都没有这样的数据,也没有这样的场景和需求,只能自己来做。
按照李想的话说,“我可以站在巨人的肩膀上,但是它只是我其中的一部分”。
其更是在访谈上直言,自己之所以将自研的整车操作系统理想星环OS给开源了,一方面是出于对DeepSeeK的感谢,一方面也是因为受到了那么大的帮助,所以自己认为应该对社会做点什么贡献,不让行业这么卷。
VLA就像一个「司机大模型」,可以像人类司机一样工作,不外VLA的诞生不是突变,而是进化,毕竟“没有办法直接吃第十个包子”。
整个过程经历了三个阶段,对应了理想汽车辅助驾驶的昨天、今天和明天。
按照李想的说法,其内部原本打算要到今年年底才能做出能够满足需求的语言模型,但DeepSeek一开源,瞬间就加速了9个月的时间。
不过DeepSeeK的开源只是加速了VLA(视觉语言行动模型)的L(language语言)的部分,像VL(视觉和语言)的组合语料,无论是OpenAI仍是DeepSeek,都没有这样的数据,也没有这样的场景和需求,只能自己来做。
按照李想的话说,“我可以站在巨人的肩膀上,但是它只是我其中的一部分”。
其更是在访谈上直言,自己之所以将自研的整车操作系统理想星环OS给开源了,一方面是出于对DeepSeeK的感谢,一方面也是因为受到了那么大的帮助,所以自己认为应该对社会做点什么贡献,不让行业这么卷。
VLA就像一个「司机大模型」,可以像人类司机一样工作,不外VLA的诞生不是突变,而是进化,毕竟“没有办法直接吃第十个包子”。
整个过程经历了三个阶段,对应了理想汽车辅助驾驶的昨天、今天和明天。

第一阶段,李想将其比喻为“昆虫动物智能”:通过机器学习感知配合规则算法的分段式辅助驾驶解决方案,有既定的规则,同时还依赖高精地图,类似蚂蚁完成任务的方式。
仅仅百万量级的参数自然无法完成更复杂的事情,因此需要不断地加限定规则,形成类似“有轨交通”的形式。
这对应了理想汽车自2021年起,通过自研依赖规则算法和高精地图的辅助驾驶方案。
而第二阶段则对应了理想汽车自2023年起研究,并于2024年正式推送的端到端+VLM(VisionLanguageModel,视觉语言模型)辅助驾驶。
李想将其称之为“哺乳动物智能”阶段:通过端到端大模型学习人类驾驶行为,比如马戏团里的一些动物像人类学习怎么骑自行车,它们能学会人类的各种行为,但其本身对物理世界的理解并不充分。
因此需要通过三维图像判断自身速度和轨迹以及在空间中所处的位置,虽然足以应对大部分泛化场景,但很难解决从未遇到过或特别复杂的问题,此时需要配合视觉语言VLM模型,但现有视觉语言模型在应对复杂交通环境时只能起到辅助作用。
第一阶段,李想将其比喻为“昆虫动物智能”:通过机器学习感知配合规则算法的分段式辅助驾驶解决方案,有既定的规则,同时还依赖高精地图,类似蚂蚁完成任务的方式。
仅仅百万量级的参数自然无法完成更复杂的事情,因此需要不断地加限定规则,形成类似“有轨交通”的形式。
这对应了理想汽车自2021年起,通过自研依赖规则算法和高精地图的辅助驾驶方案。
而第二阶段则对应了理想汽车自2023年起研究,并于2024年正式推送的端到端+VLM(VisionLanguageModel,视觉语言模型)辅助驾驶。
李想将其称之为“哺乳动物智能”阶段:通过端到端大模型学习人类驾驶行为,比如马戏团里的一些动物像人类学习怎么骑自行车,它们能学会人类的各种行为,但其本身对物理世界的理解并不充分。
因此需要通过三维图像判断自身速度和轨迹以及在空间中所处的位置,虽然足以应对大部分泛化场景,但很难解决从未遇到过或特别复杂的问题,此时需要配合视觉语言VLM模型,但现有视觉语言模型在应对复杂交通环境时只能起到辅助作用。

在端到端的基础上,才能来到第三阶段,也就是李想说的“人类智能”的阶段,给出的答案就是VLA司机大模型。
它能通过3D和2D视觉的组合,完整地看到物理世界,而不像VLM仅能解析2D图像。同时,VLA拥有完整的脑系统,具备语言、CoT(ChainofThought,思维链)推理能力,既能看,也能理解并真正执行行动,符合人类的运作方式。
李想还列举了端到端+VLM(视觉语言模型)架构可能无法解决,但VLA(视觉语言行动模型)可以解决的cornercase(长尾案例)。
至于如何训练VLA,李想也做了详细的阐述,整个过程就像人学会如何开车一样。
第一步是预训练,这一步的目标是让AI拥有对世界和交通的基础认知,就像人先学习各种交规知识一样。
在端到端的基础上,才能来到第三阶段,也就是李想说的“人类智能”的阶段,给出的答案就是VLA司机大模型。
它能通过3D和2D视觉的组合,完整地看到物理世界,而不像VLM仅能解析2D图像。同时,VLA拥有完整的脑系统,具备语言、CoT(ChainofThought,思维链)推理能力,既能看,也能理解并真正执行行动,符合人类的运作方式。
李想还列举了端到端+VLM(视觉语言模型)架构可能无法解决,但VLA(视觉语言行动模型)可以解决的cornercase(长尾案例)。
至于如何训练VLA,李想也做了详细的阐述,整个过程就像人学会如何开车一样。
第一步是预训练,这一步的目标是让AI拥有对世界和交通的基础认知,就像人先学习各种交规知识一样。

这一步放入足够多的Language,Vision的语料和token(词元)。其中Vision包含两个部分,一部分是物理世界的3DVision,另一部分是高清2DVision,然后再放入VL(视觉和语言)联合的数据,例如将导航地图和车辆对导航地图的理解同时放入训练集中。
从而形成一个VL的基座模型,然后会被“蒸馏”成一个更小、能更快运行的约32B端侧的模型,保证它运行速度足够得顺畅。
这一步放入足够多的Language,Vision的语料和token(词元)。其中Vision包含两个部分,一部分是物理世界的3DVision,另一部分是高清2DVision,然后再放入VL(视觉和语言)联合的数据,例如将导航地图和车辆对导航地图的理解同时放入训练集中。
从而形成一个VL的基座模型,然后会被“蒸馏”成一个更小、能更快运行的约32B端侧的模型,保证它运行速度足够得顺畅。
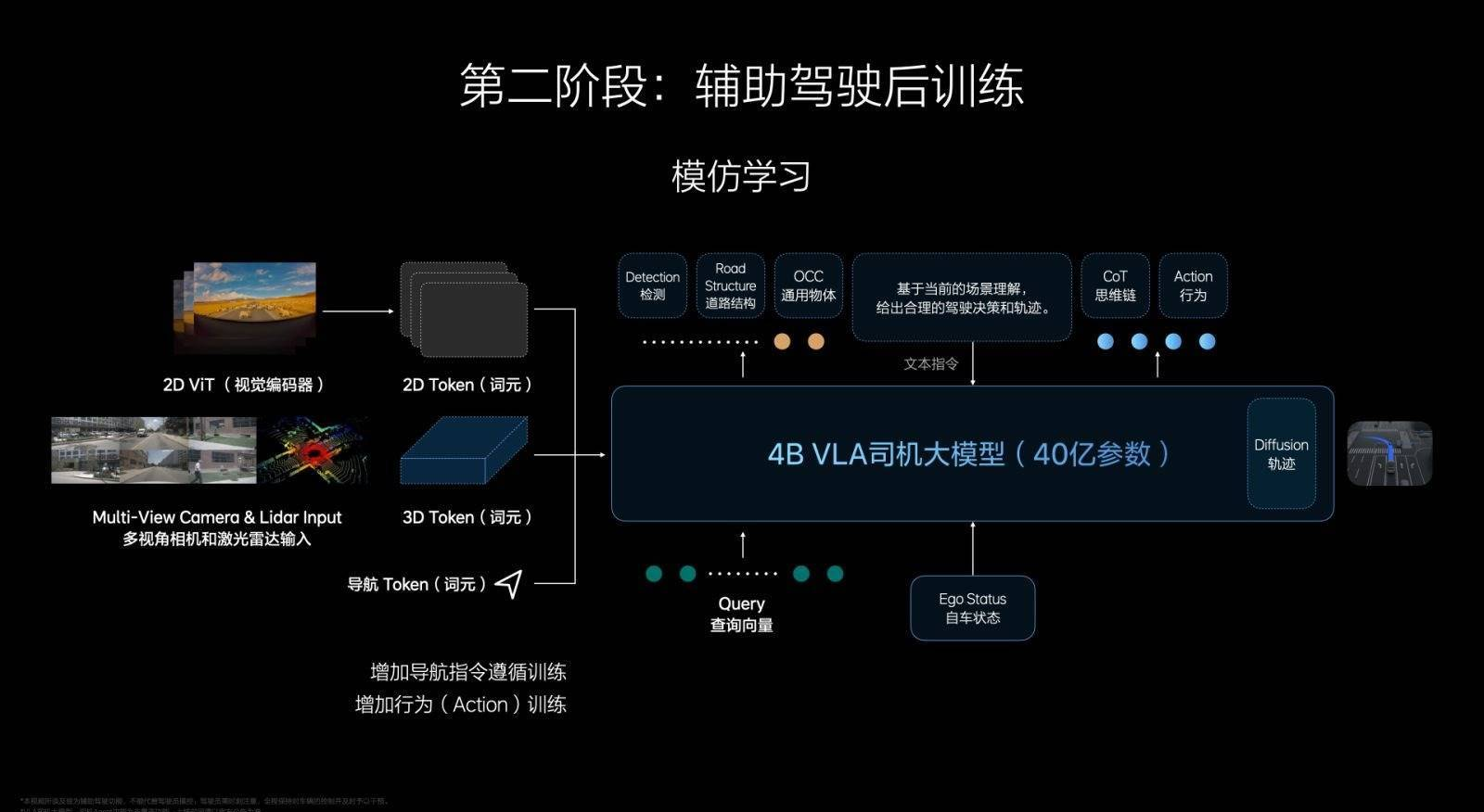
第二步是后训练,在VL的基础上加入Action,Action部分的后训练类似人类去驾校学开车,能够直接从视觉到理解再到输出,形成一个初级的VLA「端到端」模型。
李想还强调,不会做长思维链,一般是两步到三步,否则长时延会无法满足安全性。另外,当Action完成后,VLA还会根据性能做4-8秒的扩散模型(difussion),预测轨迹和环境。
第三步属于强化学习,主要分为两部分,一是RLHF,基于人类反馈的强化学习,会参考大量人类司机的驾驶数据,当它做得好时得到鼓励,做得不好的时候,会得到反馈。
同时,理想汽车搭建了一个非常逼真的虚拟“交通世界”,有点像一个超高水平的模拟器,让AI在里面自己练习,这部分属于纯粹的强化学习。
第二步是后训练,在VL的基础上加入Action,Action部分的后训练类似人类去驾校学开车,能够直接从视觉到理解再到输出,形成一个初级的VLA「端到端」模型。
李想还强调,不会做长思维链,一般是两步到三步,否则长时延会无法满足安全性。另外,当Action完成后,VLA还会根据性能做4-8秒的扩散模型(difussion),预测轨迹和环境。
第三步属于强化学习,主要分为两部分,一是RLHF,基于人类反馈的强化学习,会参考大量人类司机的驾驶数据,当它做得好时得到鼓励,做得不好的时候,会得到反馈。
同时,理想汽车搭建了一个非常逼真的虚拟“交通世界”,有点像一个超高水平的模拟器,让AI在里面自己练习,这部分属于纯粹的强化学习。
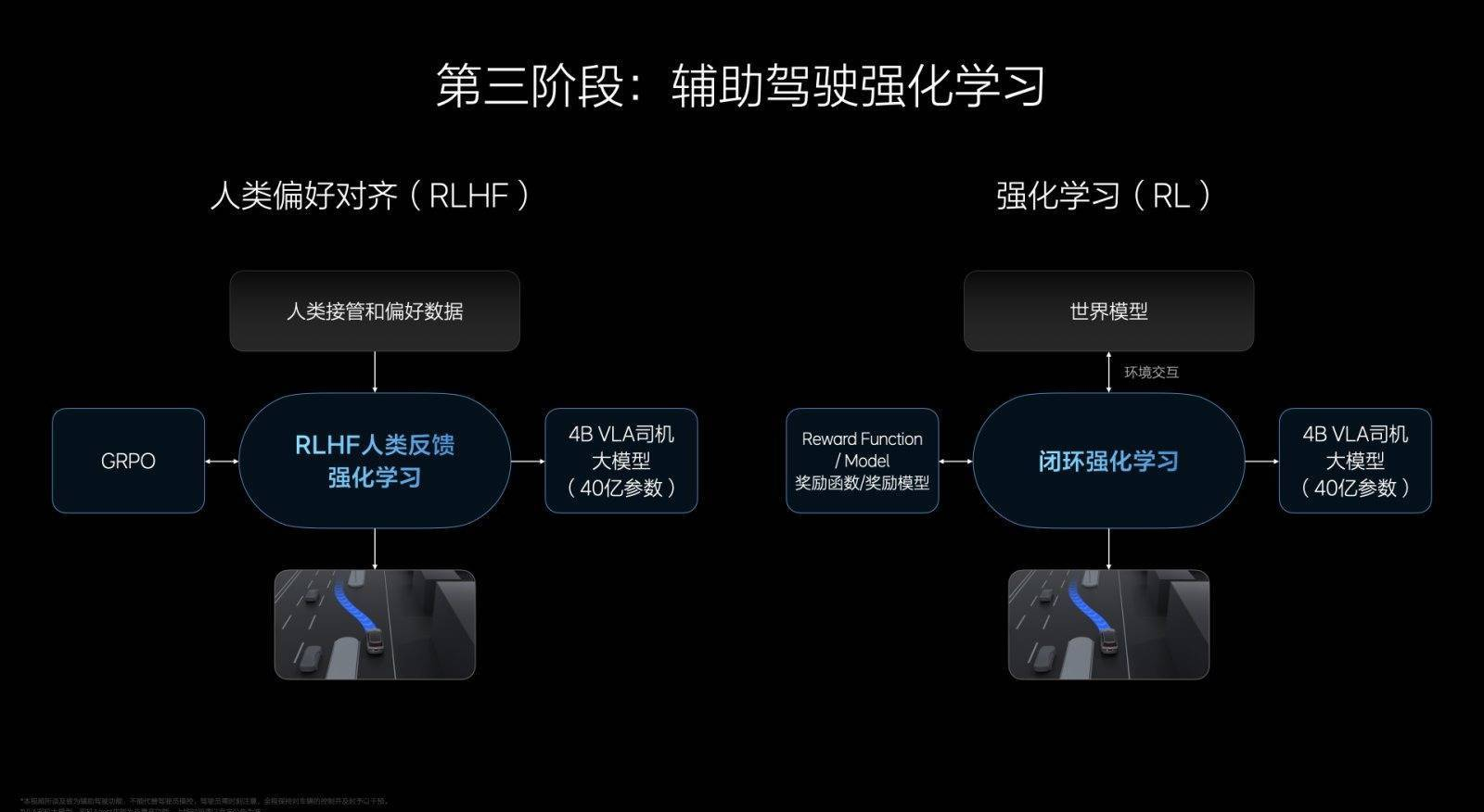
在训练指标上,理想会通过G值来判断辅助驾驶的舒适性,同时做碰撞的反馈,还有交通规则的反馈。
不难看出,第三步,就相当于人类拿到驾照后,来到社会上来开车来强化自己的驾驶技能。当这三个步骤完成了以后,VLA能够跑在车端的模型其实就产生了。
但还没有完事,这时虽然有了VLA司机大模型,但还无法做到人类跟VLA的交互,这时候理想就需要搭建一个司机Agent(智能体),用自然语言教辅助驾驶系统应该如何开车。
在训练指标上,理想会通过G值来判断辅助驾驶的舒适性,同时做碰撞的反馈,还有交通规则的反馈。
不难看出,第三步,就相当于人类拿到驾照后,来到社会上来开车来强化自己的驾驶技能。当这三个步骤完成了以后,VLA能够跑在车端的模型其实就产生了。
但还没有完事,这时虽然有了VLA司机大模型,但还无法做到人类跟VLA的交互,这时候理想就需要搭建一个司机Agent(智能体),用自然语言教辅助驾驶系统应该如何开车。
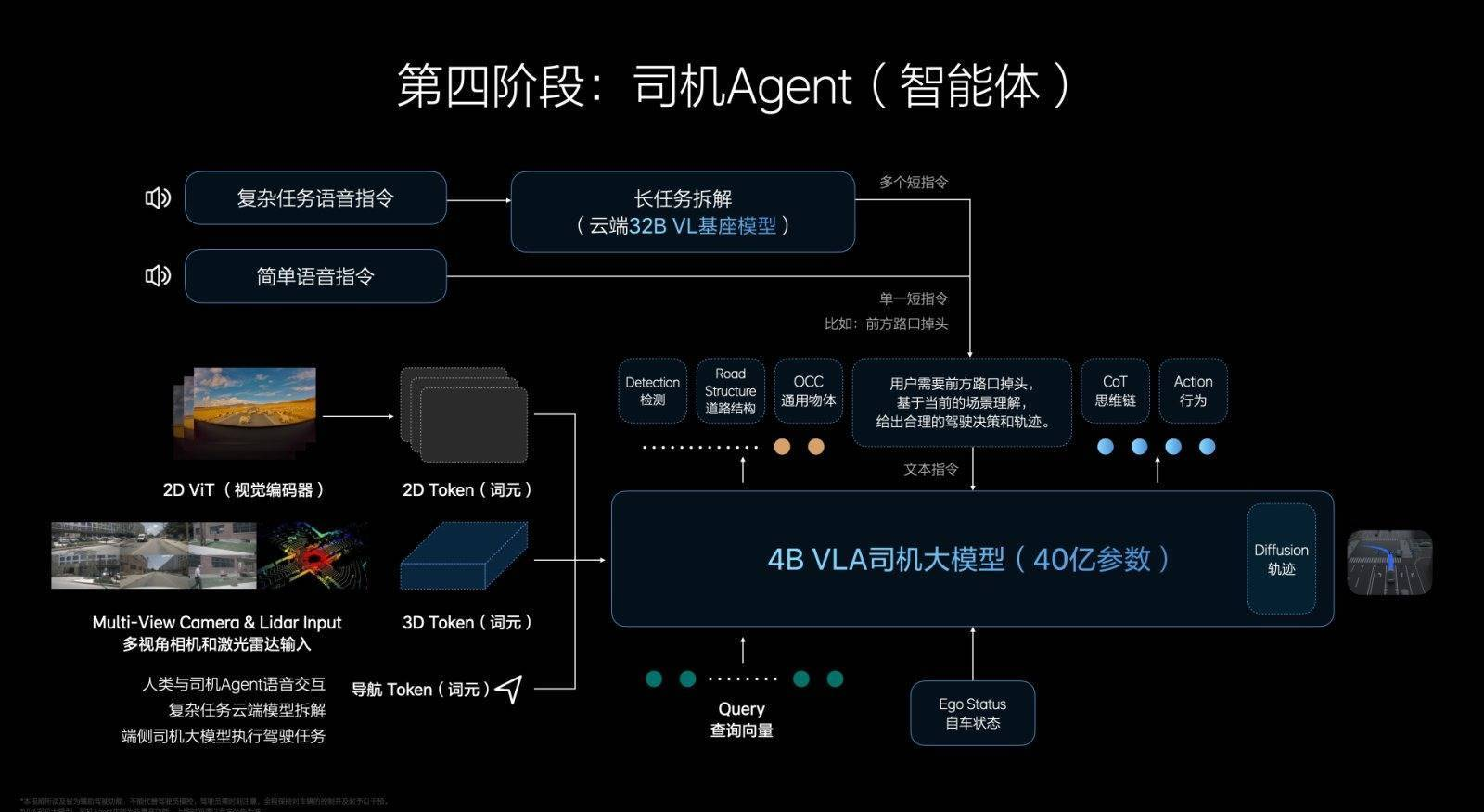
如果是一些短指令,通用的短指令VLA司机大模型直接就处理了,不需要再经过云端。如果是一些复杂的指令,其实先要到云端的32B的基座模型那里,VL(视觉和语言)处理完以后,再整个交给VLA司机大模型来进行处理。
在李想看来,VLA是现阶段能力最强的架构,它的能力是最接近人类的,甚至有机会超过人类。但不一定是最终极的架构。
“是否是一个效率最高的方式,是否有效率更高的架构出现,这些还要打个问号,我认为大概率仍是会有下一代架构的。”就像他说的那样,前面没有任何人走过这条路,理想其实走的是一个无人区。
“理想以前走的是汽车的无人区,以后走的是人工智能的无人区。”如果是一些短指令,通用的短指令VLA司机大模型直接就处理了,不需要再经过云端。如果是一些复杂的指令,其实先要到云端的32B的基座模型那里,VL(视觉和语言)处理完以后,再整个交给VLA司机大模型来进行处理。
在李想看来,VLA是现阶段能力最强的架构,它的能力是最接近人类的,甚至有机会超过人类。但不一定是最终极的架构。
“是否是一个效率最高的方式,是否有效率更高的架构出现,这些还要打个问号,我认为大概率仍是会有下一代架构的。”就像他说的那样,前面没有任何人走过这条路,理想其实走的是一个无人区。
“理想以前走的是汽车的无人区,以后走的是人工智能的无人区。”
编辑: 来源:
